Parameterized kernel specs proposal #87
Conversation
|
I imagine @kevin-bates would be interested in this too. |
|
@echarles has been exploring similar ideas in https://github.com/deshaw/ksmm |
|
There also is a issue opened in jupyter-server team-compass jupyter-server/team-compass#16 to give connect to people interested in this feature. So basically, you are adding the following stanza to the kernelspec? "metadata": {
"parameters": {
"cpp_version": {
"type": "string",
"default": 'C++14',
"enum": ['C++11', 'C++14', 'C++17'],
"save": true
}
}
},
} |
|
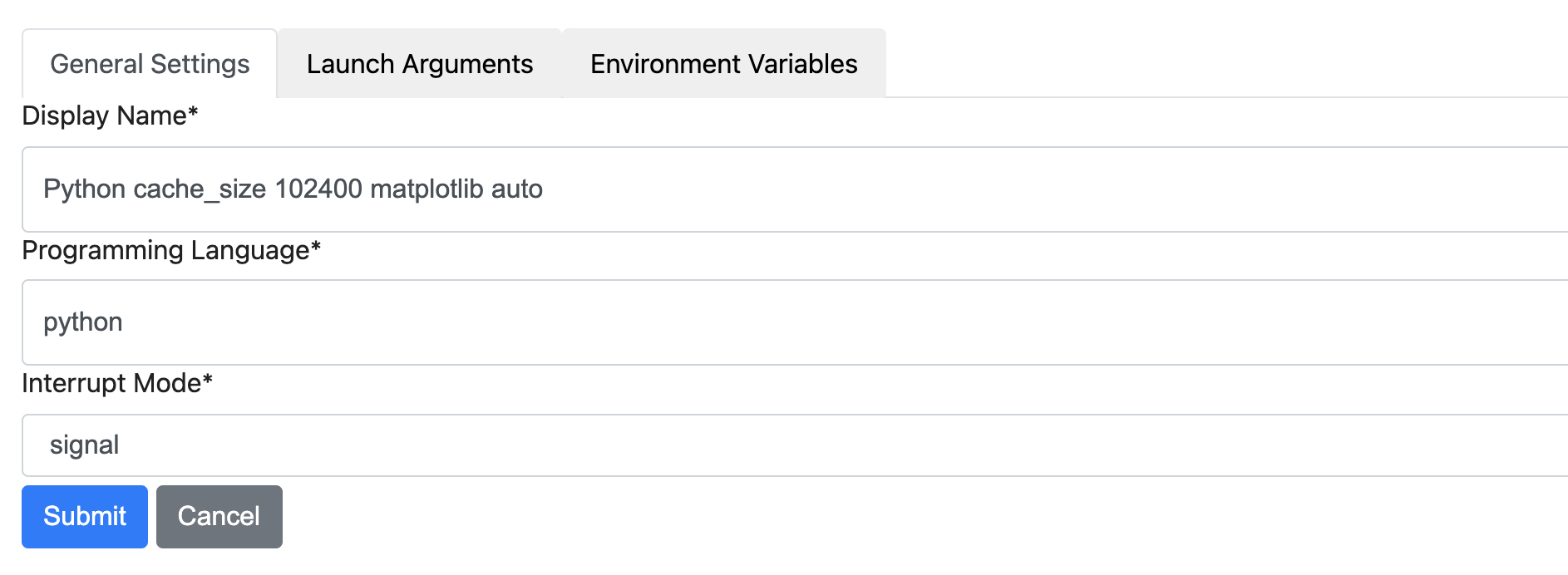
... and that stanza is a json-schema. For KSMM, we give the option to define env var (see https://raw.githubusercontent.com/deshaw/ksmm/main/screenshots/general_settings_ss.png). I read you say |
{kind=link}
|
Thanks for the ping @dhirschfeld and reference to the team-compass issue @echarles. @hbcarlos - this is great - thank you for opening this issue! I'm really hoping this proposal can be expanded a bit to also include I would love to participate in any way possible. Thank you for opening this. |
Exactly, the E.g. |
Thanks, @kevin-bates! Help is always welcome!
This proposal allows specifying parameters independently of how they may be used (as environment variables, command-line arguments). What we are trying to achieve on this JEP, is to include and formalize the concept of parameters in the kernel specs but not the semantics, so that developers can use these parameters for any purpose (provisioner parameters, environment variables, etc.). I'll update the proposal to make it more clear. |
2834bb9
to
37756a1
Compare
There was a problem hiding this comment.
This is a great start - thank you.
I'm not sure if this is necessary here but should we discuss where/how these parameters will be applied when, and when not, provided in the start request payload.
I've also been thinking about how the JSON schemas get into existence in the first place. Yes, we definitely need to support their presence in the kernel.json file (and I know @SylvainCorlay has brought up having a separate "sibling file" for the schema), but I'd also like to see a "query capability" whereby the KernelSpecManager asks the configured kernel provisioner "give me your parameter schema". This would allow the provisioner's current environment to perhaps be utilized to come up with the schema. For example, if memory were a parameter that the provisioner applies, then the provisioner could (hypothetically) detect available memory and use some heuristic to determine the range of memory values applicable to that configuration. Even if the "query" returns static information, it would go a long way to ease the kernelspec deployment burden on operators.
Of course, what is returned by the KernelSpecManager is the (possibly merged) result of these interactions, so perhaps we could drive toward that later - we should just try to make sure we don't preclude us from having this option.
(The KernelSpecManager could do the same kind of query against the underlying kernel, although that may be tougher because I'd like to see a given kernel spec have language as a parameter, where the kernel provisioner (or certain provisioners at least) support multiple kernel types. This may be pie-in-the-sky kind of stuff, but dynamic kernelspecs is where we're heading.)
| Cons: | ||
|
|
||
| - Changes are required in multiple components of the stack, from the protocol specification to the front-end. | ||
| - Unless we require default values for all parameters, this would be a backward-incompatible change. |
There was a problem hiding this comment.
I think, at a minimum, we need to require default values for all required parameters and the "source" (i.e., kernel or kernel provisioner) should have a reasonable default for others. Of course, having a default for each parameter would be a "best practice".
Where the default values probably fall down are for things like credentials, but I would argue those kinds of things are probably best retained in a backing store (e.g, configuration file or database), where any inputted values would override the persisted values.
I guess the point is that we don't want to abandon all the jupyter_client-based applications that don't have the ability to present a JSON schema for parameter selection - so some form of reasonable defaulting is necessary.
There was a problem hiding this comment.
As much as possible we need to be backwards compatible with existing kernel spec users so I'm in agreement with @kevin-bates on default values. Maybe it's fine to let the kernel fail if it's missing a parameter (or if the parameter is invalid).
|
Hi @hbcarlos, I'm not sure where this JEP stands but I'd like to try to revive it a bit. I think we should discuss some of the issues I raised in the previous comment, namely parameter discovery (which, at the time, I had referred to as "query capability"). While I think having static parameters reside in the kernel.json file is sufficient, the Moreover, this interaction should pass the By introducing this discovery mechanism, existing Because a specific kernel package may not be necessarily installed locally, I was thinking of exposing "parameter providers" via entry points. The previously referenced kernel hint would reflect the name of the kernel parameter provider that the provisioner calls to fetch the corresponding kernel parameter schema. This would allow kernel implementations to be decoupled from their parameter provider if that was advantageous. Similarly, we could have provisioner parameter providers, although since the provisioner must be locally available, the configured provisioner package could expose itself as a provisioner parameter provider. For applications using The I think by introducing discoverable parameter schemas we would essentially have "dynamic kernelspecs" which would be easier to maintain and be more backward compatible between releases (including those releases that predate parameterized kernel specs). |
|
@kevin-bates Things like "entry points", |
|
Hi @kevin-bates, Yes, I would like to revive this JEP as well. Give me a couple of days to get up to speed, and I'll get back to you. |
I understand. I just wanted to help paint a picture of how a discovery mechanism might be conceptualized. Somehow a link from the discoverer to the discoverable must be made and my terminology was something concrete that others can understand. I'll try to be more abstract in future responses. |
|
Thanks for the comments and the interest you have shown in this, @kevin-bates. After looking into the Jupyter Client, Jupyter Protocol, the Jupyter Kernel management, and discussions and JEPs about the kernel discovery framework, parameterized kernel launch, kernel providers, etc. In my opinion, your comments in #87 (comment) are out of the scope of this JEP. They might take advantage of the parameterization of the Kernel Specs we propose here. In addition, Kernel Provisioners could be an excellent example to show the necessity of parameterized Kernel Specs. I just wanted to clarify with you. In this JEP, we want to formalize the introduction of parameters to the Kernel Specs. We are trying to introduce parameters for everyone to take advantage of it, from provisioners to kernels. The idea is to make it as generic as possible to include every possible use case. |
|
Thanks for your response @hbcarlos.
By this comment, it sounds like there will be pending updates to take into account parameters that are kernel-provisioner-relative - which is great. Thanks. Will these be conveyed in separate stanzas so that things like discovery (and dynamic kernelspecs) could be implemented? |
| "type": "string", | ||
| "default": "C++14", | ||
| "enum": ["C++11", "C++14", "C++17"], | ||
| "save": true |
There was a problem hiding this comment.
Would it make sense to have a format_string meta-property so software that launches the kernel can simply build the rest of the argv stanza on the fly? Otherwise, the baked-in argv in the kernel.json dictates what parameters will be used, yet users may want to include others that are defined in the schema. For example, in this example, parameters xeus_log_level will never be included despite the user wanting to enable TRACE output.
| "save": true | |
| "save": true, | |
| "format_string": "-std={cpp_version}" |
Then, only those parameters that have been provided by the user (or are required) would be included in the finalized argv list.
There was a problem hiding this comment.
The xeus_log_level parameter is used in the environment variable:
env: [
"XEUS_LOGLEVEL={parameters.xeus_log_level}"
],
That's why we are trying to make it as generic as possible so we can use these parameters anywhere.
Maybe the format_string is helpful for flags or optional parameters. I don't have an example right now but imagine a kernel with an optional flag to activate or deactivate LSP (Language Server Protocol) features.
{
"display_name": "C++",
"argv": [
"/home/user/micromamba/envs/kernel_spec/bin/xcpp",
"-f",
"{connection_file}",
"{parameters.lsp}"
],
env: [
"XEUS_LOGLEVEL={parameters.xeus_log_level}"
],
"language": "C++"
"metadata": {
"parameters": {
"lsp": {
"type": "string",
"default": "True",
"format_string": "--lsp",
"save": true
}
}
},
}
To be honest, I don't have a strong opinion on this. More people could chime in.
There was a problem hiding this comment.
The xeus_log_level parameter is used in the environment variable:
Ah - I'm sorry, I missed that. I figured environment variables would be classified in a different manner. In that vein,
I think there should be a means of adding environmental variables, free form, and those that are specified in the schema should be classified as environment variables to assist in UX. These are the kinds of things that integrations typically need and we should enable the ability to add any environment variable to the env of the kernel.
| ], | ||
| "language": "C++" | ||
| "metadata": { | ||
| "parameters": { |
There was a problem hiding this comment.
Since these will include provisioner-relative parameters, I think it would be good to have separate kernel_parameters and provisioner_parameters stanzas - both for end-user applications and programmatic processing.
There was a problem hiding this comment.
- Cdsdashboards does provisioning atop JupyterHub (~BinderHub but with parameters)
README:
- User sees a safe user-friendly version of the original notebook - served by Voilà, Streamlit, Dash, Bokeh, Panel, R Shiny etc.
All of this works through a new Dashboards menu item added to JupyterHub's header.
There was a problem hiding this comment.
- jupyter-repodocker looks for REES config files like {requirements.txt, environment.yml, Dockerfile} in / and /.binder/ ; but there are also command line argument parameters:
https://repo2docker.readthedocs.io/en/latest/usage.html#command-line-api
There was a problem hiding this comment.
Since these will include provisioner-relative parameters, I think it would be good to have separate kernel_parameters and provisioner_parameters stanzas - both for end-user applications and programmatic processing.
It is okay for me to distinguish between kernel and provisioner. Nevertheless, I believe we should not distinguish them because provisioner parameters will get a form for free once we implement the form for choosing kernel parameters.
For example, in JupyterLab, when a user selects the kernel, if there is a custom provisioned, they will see and be able to configure parameters like (CPU, GPU, and memory) from the same form.
There was a problem hiding this comment.
Nevertheless, I believe we should not distinguish them because provisioner parameters will get a form for free once we implement the form for choosing kernel parameters.
For example, in JupyterLab, when a user selects the kernel, if there is a custom provisioned, they will see and be able to configure parameters like (CPU, GPU, and memory) from the same form.
I understand, but users should know that certain parameters are relative to the provisioned environment while others are relative to the kernel. In addition, their metadata specifications in the schemas will be separated, so their values should remain separated as well.
If they don't separate them, then users will see completely different sets of parameters for the "same kernel" depending on the provisioner and (I believe) it makes sense logically to separate the two. That said, the UX can choose how these should be organized but at least they'd have that option if the two are separated in their schemas and submission values.
There was a problem hiding this comment.
I don't think that we need to give a specific semantics to the new kernel parameters, since they are completely generic and can have very different semantics depending on the use case (language version, connexion parameters, options, or anything else).
|
Specifically which things need to be parameterized at the kernel level? "Reproducibility" is jeopardized if all parameters are not persisted for repeatability. Which additional files would then also be necessary to archive and distribute in order to reproduce the notebook output? Variance in parameters like PYTHONHASHSEED and PYTHOPTIMIZE should also be isolated (for Python notebooks, for example). Should you also with this measure specify how users should document such non-kernel simulation parameters? E.g cookiecutter has a config schema with default values IIRC, but it doesn't specify e.g. jsonschema or SHACL to validate runtime parameter datatypes or constraints, and I don't think Users will want to pass urlargs to the kernel from URL arguments and HTML form data, but that runs How do I determine whether or not an experimental outcome is sensitive to these new unspecified parameters? What additional risks to reproducible science and users is posed by adding parametrization to os commands? |
If defaults could change over time, the reproducible ScholarlyArticle author must persist and archive at time t and publish the default values that were specified at that time, too |
It is up to the kernel. We just offer the possibility of having parameters.
That is addressed in this JEP. We talk about adding a particular attribute
We could do a sanity check before launching the kernel.
The user can now open a terminal and run |
Parameterized kernel specs
In this JEP we propose to parameterize the kernel specs, simplifying the way some kernels are installed reducing the amount of kernel specs files, and at the same time improving the UI of some of the Jupyter front-ends.
Co-author: @SylvainCorlay
Contributors that may be interested in this topic from past conversations: