Generating and maintaining a Master set from assets reported by various third-party vendors, internal source systems, and systems integrated in-cases of acquisitions and mergers, at one central data-hub repository is challenging. A ‘single version of truth’ maintained for associated entities across the entire organization’s data sources, can help orchestrate collaboration between multiple cross-functional channels of the business.
This repo focuses on masterizing clinical data in terms of hospitals/sites, that the pharmaceutical client managed. The datasets used in this repository are open-sourced and available for free at pbpython: Master Data.
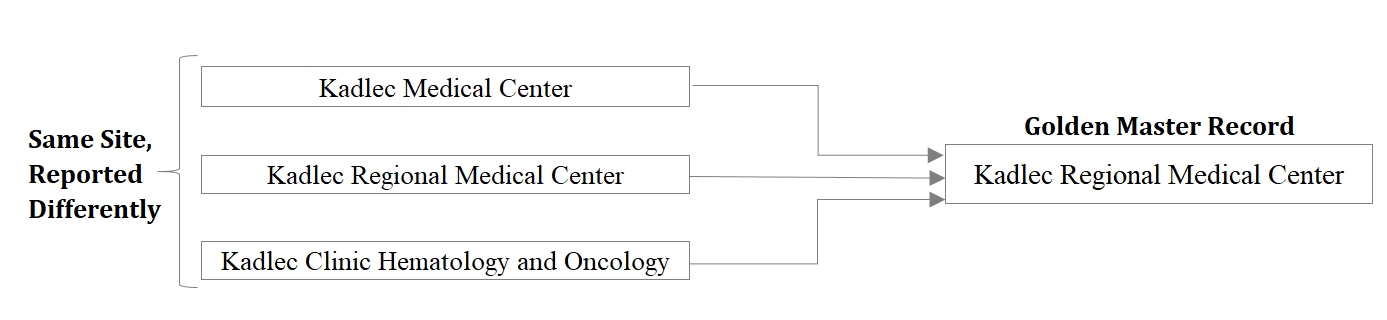
For example- the same site “Kadlec Regional Medical Center”, might be reported differently as “Kadlec Clinic Hematology and Oncology” but with the same address, across the client’s source systems. Our goal is to identify a golden entity (Master Record) to which other duplicate records can be matched, and maintain their source-to-master linkage (Cross-Reference). Although industry-standard tools are available (Informatica, Oracle, SAP, etc.) that can be used with third-party collaborators like Address-Doctor-Service, or Dun&Bradstreet to retrieve the standardized asset data, this repo was intended to prove that open-source code and libraries can produce near-standardized results.
For de-duplicating records and generating a master set, we compute the similarity between two textual strings and determine if they are a probabilistic data match. If two or more records seem to belong to the same golden entity i.e. the Master record, they are ‘linked’ together. The intuition behind this procedure is as follows:
Within a dataset of n records, we must compare the 1st record with the remaining (n - 1) records, the 2nd record with the remaining (n - 2) records, and so on. Thus, there would be nC2 = ( n*(n-1)/2 ) unique combinations to be considered.
Between 2 different datasets of m and n records each, there will be ( m*n ) such unique combinations.
The RecordLinkage library in R provides two main functions to generate ( n*(n-1)/2 ) candidates for deduplication within a single dataset (hereafter called the dedup function), or ( m*n ) candidates for identifying duplicates between two different datasets (hereafter called the linkage function)
Most importantly, machine-learning techniques like clustering or classification algorithms, weren’t applicable since there wasn’t a target variable/list to train or test on. Hence, the goal was to leverage Levenshtein similarity scores to compare text holistically and link records together.
i. The output of these R-functions can be interpreted as the raw universe of potential duplicates for that minibatch; a DataFrame containing the following columns: [ Source-Id, Master-Id, Site-Name-Comparison-Score, State-Comparison-Score, City-Comparison-Score, Address-Comparison-Score, Postal-Code-Comparison-Score ]
ii. The source-record can match against multiple master-records with a total match-score ≥ 4. We choose the best match for incoming source-records based on the highest total score for all its potential master-records (a Greedy Approach).
iii. There are cyclic cases in these score outputs like-
> Record B matches against Record A
> Record C matches against Record B
Ideally, we should transitively maintain:
> Record C matches against Record A
These cyclic occurrences may extend to upwards of 10-15 such transitive linkages, so handling them efficiently is crucial.
iv. Finally, from this list of cleaned-normalized-score-features, using basic set-theory we find the unique list of masters. Consider ‘SR_NUM_1' as the list of incoming Source-Ids, and 'SR_NUM_2' as the Master-Ids to which ‘SR_NUM_1’ should be linked based on match-score. ‘SR_NUM’ of the entire minibatch, will be the universe of records. Union of 'SR_NUM_1' & 'SR_NUM_2' will be the universe of potential duplicates (UPD). Stand-alone records in the current minibatch, are those which do not fall in this universe of potential duplicates (Non-UPD). The final Master-records will be the union of Master-Ids and the Stand-alone Ids identified above.


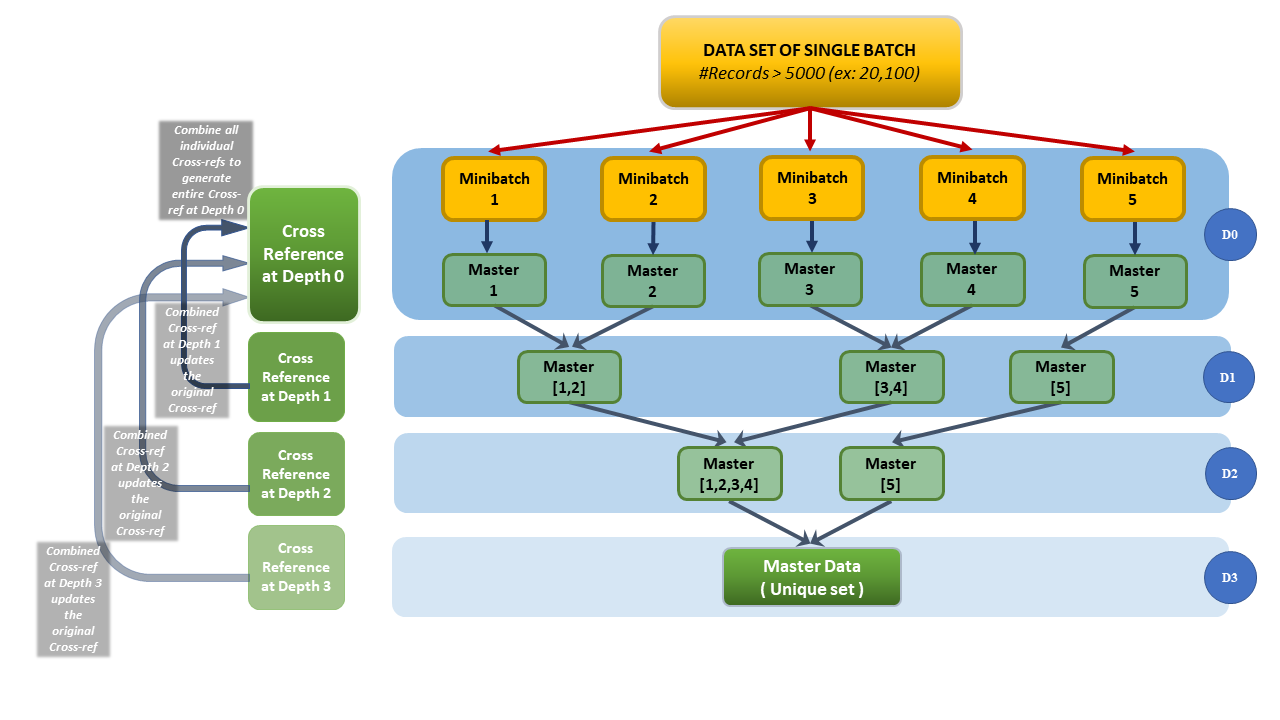
v. A recursive algorithmic approach will first pass minibatches of a fixed size into the dedup R-function and generate deduplicated master-datasets.
These deduplicated master-datasets would be compared against each other using the linkage R-function. This is similar to the conventional level-order traversal of a binary tree using a queue, but in reverse, until each record is compared against every other. The motivation here is to prevent overuse of RAM, due to in-memory candidate pair computations.
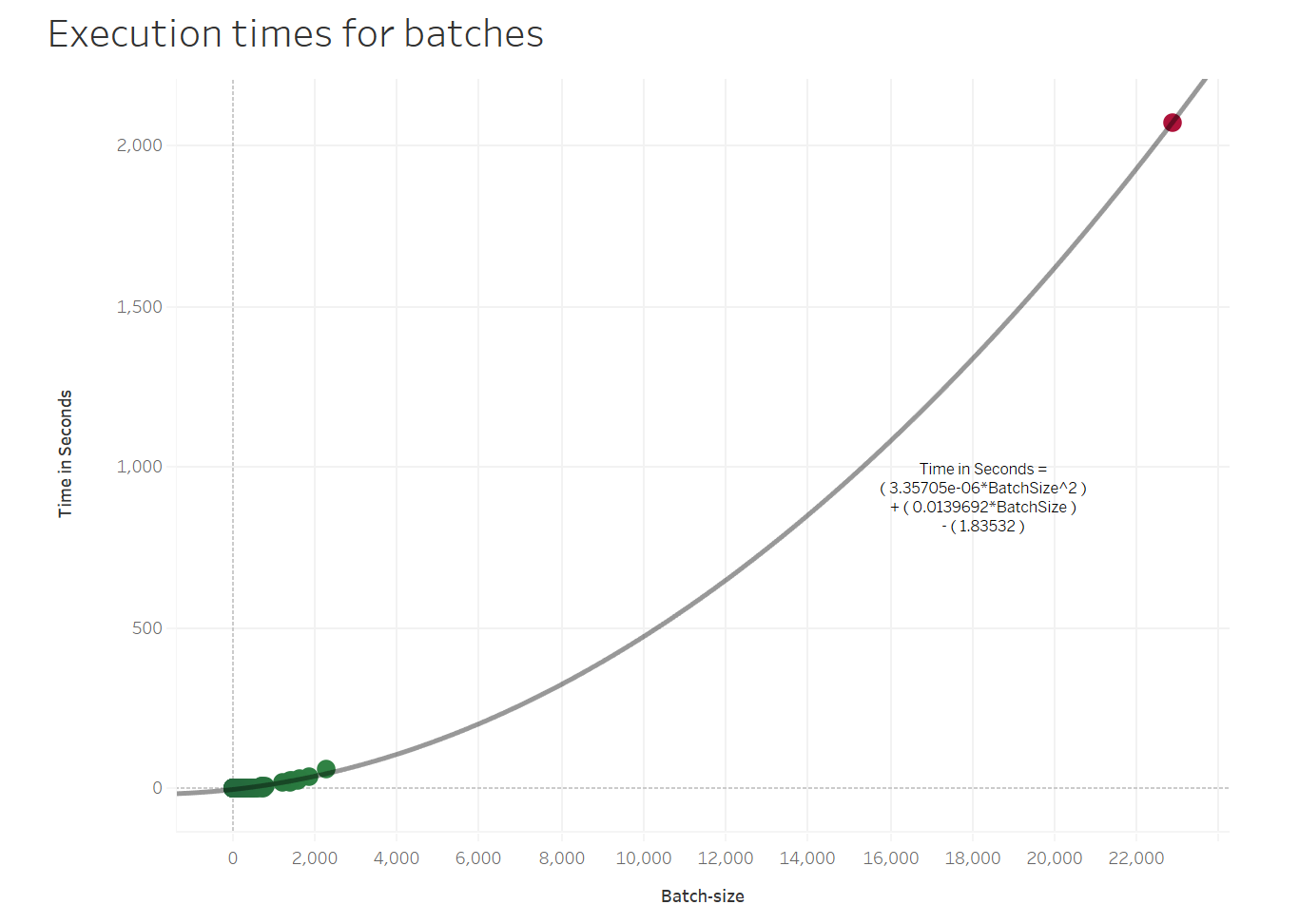
vi. The time taken for recursively processing a large batch is significantly lower than the time that would’ve been theoretically required for one-shot processing.
The following observations were taken by considering minibatches of size 5,000, on an AWS EC2 instance m5.4xlarge (64 GB RAM, and 16 vCPUs- each a single thread on a 3.1 GHz Intel Xeon Platinum 8175M processor):
Masterize_data_Text_similarity_scores.pdf
-
Install GIT (This repo used 2.25.1 on Windows-10): Git
-
Install Python (This repo was built on 3.8.1 but is compatible with 2.5x): Python
-
Download this repository: Masterize_Hospital_Entities
-
Set up Jupyter Notebook using Anaconda or Visual Studio Code
- VS Code has a Jupyter Notebook extension now
- Set up Spark and Pyspark: Apache PySpark for Windows 10
- Note- There seems to be a known issue with Apache Spark and latest Java versions, I have used OpenJDK 13.0.2
-
Install R and R-studio (This repo was built on 4.0.4 but is compatible with 3.4x): R and RStudio Note- We'll use the x86 version of R within R-Studio; reason mentioned in the following step.
-
Set up R-tools for working with binaries of the levenshtein.c for fast text-comparison: Rtools40
- Note- To generate the binaries from the levenshtein.c file, you need to switch into the 32-bit mode of R (x86), and then run the first command in shell.
- Then the R-script will be able to load the binary file during runtime as follows:
> R CMD SHLIB levenshtein.c
>> dyn.load('levenshtein.dll') for Windows or '.so' for Linux
- Create a virtual environment for making a copy of your system-wide Python interpreter, in the directory for this repo:
> python -m venv masterdataenv
- Activate this virtual environment. You need not perform step#4 each time for execution:
> masterdataenv\Scripts\activate
- Install the application-specific dependencies by executing:
> pip install -r requirements.txt
-
Set up your input data in /Data_Files/hospital_account_info_raw.csv with the expected structure.
-
Changes within config.py:
- Construct your thresholds for individual text-comparison.
- Point the x86 version of R-environment to enable execution of dyn.load('levenshtein.dll') on line #48.
- Switch the binary-extension value on line #57 / #58 based on your system being Windows/Unix.
- Execute the Recursive_Python_Site_Master.py script:
> python Recursive_Python_Site_Master.py > Recursive_Python_Site_Master.log
- Your final Cross-Reference Report and Master-Data Report, both will be created in /Data_Files/Master_Data/ directory.